VLA Models: The “ChatGPT Moment” for Autonomous Driving in 2026
SEO Slug: vla-models-autonomous-driving-2026
The autonomous driving industry has reached what many experts describe as its “ChatGPT moment.” For years, self-driving technology relied primarily on rigid, rule-based systems and resource-intensive high-definition mapping. However, 2026 has marked a definitive shift toward a more fluid, intelligent paradigm: the Vision-Language-Action (VLA) model.
By integrating the reasoning capabilities of Large Language Models (LLMs) with real-time visual perception, VLA models allow vehicles to do more than just follow a set of programmed instructions—they enable them to reason through their environment. This breakthrough is more than just a technical milestone; it is fundamentally altering safety profiles and operational scalability across the global mobility sector.

📖 Table of Contents
- What Are Vision-Language-Action (VLA) Models?
- The Shift from Rule-Based to Reasoning-Based Autonomy
- Key Players Leading the VLA Revolution
- Hardware Evolution: Solid-State LiDAR and Beyond
- Challenges and Ethical Considerations
- FAQs
Key Takeaways
- Reasoning Power: VLA models bring sophisticated judgment to vehicles, allowing them to handle complex, “long-tail” scenarios that often challenged previous systems.
- Rapid Deployment: The shift to VLA technology can help compress city launch times from years to just several months.
- Hardware Evolution: VLA models are enabling a transition from expensive rotational LiDAR to more cost-effective solid-state alternatives.
- Global Momentum: Companies like NVIDIA, Waymo, and Xpeng are at the forefront of sharing these technologies to help accelerate global adoption.
What Are Vision-Language-Action (VLA) Models?
At its core, a Vision-Language-Action (VLA) model is a multimodal framework that combines vision (sensor data), language (common-sense reasoning and instructions), and action (driving commands) into a single, unified network. Unlike traditional modular systems where information could be lost during handoffs between perception and planning, VLA models maintain context throughout the entire decision-making process.
Featured Snippet: Vision-Language-Action (VLA) models are advanced AI architectures that integrate visual perception with the linguistic reasoning of Large Language Models. In 2026, these models enable autonomous vehicles to interpret complex traffic scenarios, follow natural language commands, and make transparent, reasoning-based decisions, effectively augmenting traditional rule-based programming.
This architecture allows a vehicle encountering an unusual obstacle—such as a mattress on a highway or a ball rolling into the street—to draw on general world knowledge to predict likely outcomes and act accordingly.
👉 Top
The Shift from Rule-Based to Reasoning-Based Autonomy
For much of the last decade, autonomous vehicle (AV) development was often hindered by the “long tail” of driving—those rare, unpredictable events that human drivers handle instinctively but that machines found difficult to categorize.
Traditional systems could be “decision-poor” under pressure because they lacked an intrinsic understanding of physical dynamics. VLA models address this by introducing “Chain-of-Thought” (CoT) reasoning. When a pedestrian is detected, the system doesn’t just stop; it can output a textual explanation: “Pedestrian crossing detected; slowing down and stopping.” This transparency is critical for building public trust and meeting the evolving regulatory requirements emerging in 2026, particularly in Europe and the UK.
👉 Top
Key Players Leading the VLA Revolution
The VLA landscape in 2026 is characterized by a mix of established tech giants and innovative startups:
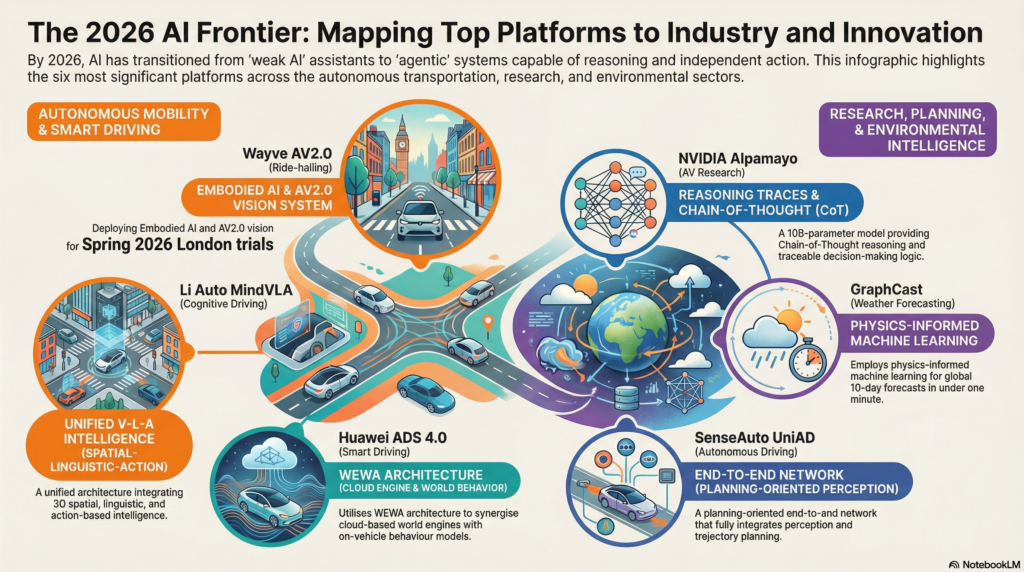
- NVIDIA: With the release of the Alpamayo 1 reasoning VLA model, NVIDIA has provided the research community with a 10-billion-parameter architecture that is currently available as an open-source resource on Hugging Face.
- Xpeng: The automaker recently announced VLA 2.0, which is trained on extensive driving datasets. This model allows their fleet to interact with the physical world in real-time without relying heavily on HD maps.
- Waymo: Utilizing its foundation models, the company aims to deliver one million rides per week by the end of 2026, expanding its footprint across numerous US cities.
- Wayve and Uber: In London, these partners are launching Level 4 autonomous trials, tackling complex urban driving environments using an “Embodied AI” approach that learns to navigate diverse locations.
👉 Top
Hardware Evolution: Solid-State LiDAR and Beyond
One of the most significant shifts in 2026 is the changing hardware requirements for high-level autonomy. Because VLA models are highly efficient at processing visual data, they allow manufacturers to substitute expensive rotational LiDAR sensors with lower-cost solid-state alternatives and high-dynamic-range cameras.
This reduction in hardware complexity is expected to support a significant expansion of the global autonomous fleet between 2026 and 2030, moving the technology from niche pilot programs toward becoming a standard feature of modern transportation infrastructure.
👉 Top
Challenges and Ethical Considerations
Despite rapid progress, the road to “total autonomy” involves ongoing refinement. Safety remains the defining characteristic of Level 4 systems. Recent research has highlighted that while VLA models are more flexible, they can still face challenges under extreme lighting changes or highly cluttered environments.
Furthermore, as AI systems take on more responsibility, the question of liability remains a priority. Regulators like the EASA and UK CAA are currently developing frameworks for “AI trustworthiness,” working to ensure that decisions made by a VLA model are traceable and auditable.
👉 Top
FAQs
1. What is the difference between Level 3 and Level 4 autonomy? Level 3 requires a human driver to be ready to intervene when requested. Level 4 allows the vehicle to handle all driving tasks within specific zones or conditions without any human intervention.
2. Why is VLA technology considered a “breakthrough” for 2026? VLA technology supplements thousands of lines of “if-then” code with a reasoning engine that can adapt to scenarios it has not previously encountered, which can significantly increase safety and reduce deployment time.
3. Will VLA models make self-driving technology more accessible? It is likely. By relying more on intelligent software and less on high-end rotational sensors, the overall cost of the autonomous stack is declining, making large-scale deployment more feasible for public and private fleets.
4. How do VLA models improve safety? VLA models can help reduce human error and provide “explainable” decision-making, allowing developers to better understand why a vehicle took a specific action during an event.
Conclusion
The emergence of Vision-Language-Action models in 2026 represents a significant paradigm shift for autonomous systems. The industry is moving past the era of isolated pilot projects and entering a period of commercial-scale operations. As the sector continues to mature, the focus will likely shift from whether the car can drive itself to how well it can reason with the world around it. For tech enthusiasts and researchers, the coming year promises to be among the most transformative in the history of modern transportation.
Further Reading
- 🔗 NVIDIA – AI & Autonomous Vehicle Research
- 🔗 Waymo – Self-Driving Technology Updates
- 🔗 Xpeng – Smart Driving Technology
- 🔗 Hugging Face – Open-Source AI Models
👉 Top